AI Engineering in Java | Part 2


In the last post in this open ended series of explorations how to build AI applications in Java, we set up our tech-stack: Langchain4j, Quarkus and Vaadin, added a very basic ChatBot class and a message UI to play with. We saw that the results where quite impressive with the tools we chose. But some things bothered us immediately: the markdown output of the model wasn't parsed and formatted correctly; there was a gross lag between chat input and model output with no sane user feedback like streaming token per token as they come in from the model. So these are the things we're going to do in this part – at some lower level:
- Streaming the LLM output.
- Parsing and formatting the markdown output.
Gently down the stream!

Let's look back at our ChatResponse object we got back from our LLM when we issued a ChatRequest:
ChatResponse aiReply = model.chat(userMessage);
MessageListItem aiMessageItem = new MessageListItem(
aiReply.aiMessage().text(),The ChatResponse holds two objects: the ChatMessage (in our case of type AiMessage) and a ChatResponseMetadata object, which you can use for logging and monitoring your chat models (we'll do this in a later part of this series). The AiMessage has a simple text field of type String.
So what's happening is this: you send a Request to the model with some text, the model processes this text internally (creating an embedding) and generates an output token by token, till it reached some stop signal: either it reached (better: predicted) an end-of-sequence-token (<EOS>) or some maximum number of output tokens (see here for an explanation). When it has finished generating the text it sends it back in the ChatResponse object. So that's why there's a gap between input and output, because the generation takes some time (more time for bigger models, or some kind of pipeline, where the model has to fetch additional content or the output is first validated by some other model and so on).
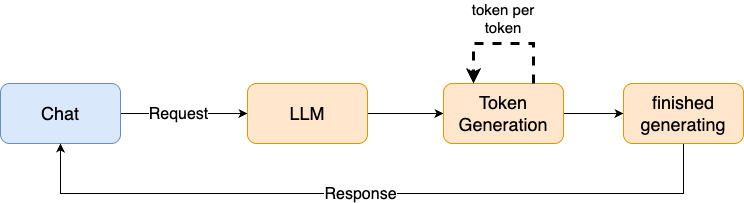
Therefore the “normal” behavior of chat applications today is to output every token immediately when it is generated, so generating a kind of stream of tokens. This is a sane feedback for the user that something is happening almost instantaneously. Mostly all of the bigger models have the functionality of streaming built into.

To use the models streaming capability, we have to incorporate the StreamingChatLanguageModel interface instead of the ChatLanguageModel. We create a new class BasicStreamingChatModel.java in /src/main/java/de/datenschauer/ai:
@SessionScoped
public class BasicStreamingChatModel implements Serializable {
static final String MODEL_NAME = "gemma3";
static final String BASE_URL = "http://localhost:11434";
OllamaStreamingChatModel model;
List<ChatMessage> chatHistory = new ArrayList<>();
public BasicStreamingChatModel() {
this.model = OllamaStreamingChatModel.builder()
.modelName(MODEL_NAME)
.baseUrl(BASE_URL)
.httpClientBuilder(new JdkHttpClientBuilder())
.build();
}
...
}The StreamHandler
Now we use the OllamaStreamingChatModel instead of the plain OllamaChatModel. Same stuff as before, but the call to the model works different now. Not only do we need the list of messages to give to the model but also some kind of handler which can handle the partial output of the model. The handler must be an implementation of the StreamingChatResponseHandler which needs to incorporate three methods for what's happening with the output .onPartialResponse(String s), .onCompleteResponse(ChatResponse r) and .onError(Throwable t). To work with our chat interface we need to ad our own handler class. So add a MyStreamingHandler class to /src/main/java/de/datenschauer/ai:
public class MyStreamingHandler implements StreamingChatResponseHandler {
private final Consumer<String> partialResponseHandler;
private final Consumer<ChatResponse> completeResponseHandler;
public MyStreamingHandler(Consumer<String> partialResponseHandler,
Consumer<ChatResponse> completeResponseHandler) {
this.partialResponseHandler = partialResponseHandler;
this.completeResponseHandler = completeResponseHandler;
}
@Override
public void onPartialResponse(final String input) {
partialResponseHandler.accept(input);
}
@Override
public void onCompleteResponse(final ChatResponse response) {
completeResponseHandler.accept(response);
}
@Override
public void onError(final Throwable t) {
// Will not be implemented right now
}
}We add two Consumer<T> to the constructer, which will handle every token coming from the model, and the final ChatResponse from the model. We use Consumer so we can later add lambda functions in the Vaadin view to handle updating the ui accordingly.
Communicate with the model – but responsively!
But first let's add the chat() method in the BasicStreamingChatModel to interact with the model. As all the methods are void in the stream handler and will be incorporated inside the view accordingly, our new chat() function will also be void. The only thing it does is: take in a handler (besides the user message) and call the doChat() method from the OllamaStreamingChatModel:
public class BasicStreamingChatModel implements Serializable {
...
public void chat(final ChatMessage userMessage, final MyStreamingHandler handler) {
chatHistory.add(userMessage);
this.model.doChat(
ChatRequest
.builder()
.messages(chatHistory)
.build(),
handler
);
}
}Pushing Vaadin to the limit
Now we can add a chat view, which can incorporate our new streaming logic. Add a StreamingChatView to /src/main/java/de/datenschauer/ui :
@Route("/streamchat")
@PageTitle("AI Streaming Chat")
public class StreamingChatView extends VerticalLayout {
@Inject
BasicStreamingChatModel model;
private static final String USER_NAME = "You";
private static final String AI_NAME = "Assistant";
private final MessageList messageList = new MessageList();
private final List<MessageListItem> messages = new ArrayList<>();
public StreamingChatView() {
setSizeFull();
setSpacing(false);
setPadding(false);
setMargin(false);
messageList.setWidthFull();
messageList.setHeightFull();
messageList.setItems(messages);
MessageInput messageInput = new MessageInput();
messageInput.setWidthFull();
messageInput.addSubmitListener(e -> handleUserMessage(e.getValue()));
add(messageList, messageInput);
}
private void handleUserMessage(String text) {
if (text == null || text.trim().isEmpty()) return;
MessageListItem userMessageItem = new MessageListItem(
text.trim(),
Instant.now(),
USER_NAME
);
userMessageItem.setUserColorIndex(1);
messages.add(userMessageItem);
ChatMessage userMessage = UserMessage.from(text.trim());
// we start with an empty MessageItem, which will be updated continuously
// in the streamLLMResponse method
MessageListItem aiMessageItem = new MessageListItem(
"",
Instant.now(),
AI_NAME
);
aiMessageItem.setUserColorIndex(2);
messages.add(aiMessageItem);
messageList.setItems(messages);
streamLLMResponse(userMessage, aiMessageItem);
}
private void streamLLMResponse(ChatMessage userMessage, MessageListItem item) {
// TBD!
}
}Looks nearly exactly like the ChatView from part one of the series. But now we immediately create the MessageListItem for the AI response with an empty string and add it to the MessageList. Our plan is, to update this item continuously when tokens are streaming in from the model. But to do this, we need to know a bit about how Vaadin updates it's ui elements.
Vaadin doesn't automatically update the ui when rendered components change. You have to instruct Vaadin to actively push elements from the server to the client via websocket connection when they change and to render them anew by the client. Oh no – this sounds complicated, doesn't it? But Vaadin actually makes this really easy for us! In fact it's just adding one annotation and calling two UI functions. Let's see how this works:
public class StreamingChatView extends VerticalLayout {
...
private void streamLLMResponse(ChatMessage userMessage, MessageListItem item) {
var partialText = new StringBuilder();
var handler = new MyStreamingHandler(
token -> {
partialText.append(token);
// Use UI.access for thread-safe updates
getUI().ifPresent(ui -> ui.access(() -> {
item.setText(partialText.toString());
messageList.setItems(messages); // Refresh the message list --> will update ui!
}));
},
response -> // what to do here?!
);
model.chat(userMessage, handler);
}
}First we instantiate a StringBuilder to hold the accumulating text, where the tokens are added when they come in. This is managed by our MyStreamingHandler: it takes in two anonymous functions – one for what's happening with the tokens, and one for what's happening with the final response (but we leave this aside for now). Here we see Vaadin's convenience function getUI() which returns access to the current rendered UI for thread safety issues. Then via the .access() method we can access the elements in the UI. There we will reset the text of the MessageListItem to the partially accumulated string of the StringBuilder and then update the MessageList with .setItems(). This will push the new MessageList to the browser and update the UI. But when exactly does the push happen? We didn't specify it right now. This is where the @Push annotation comes in.
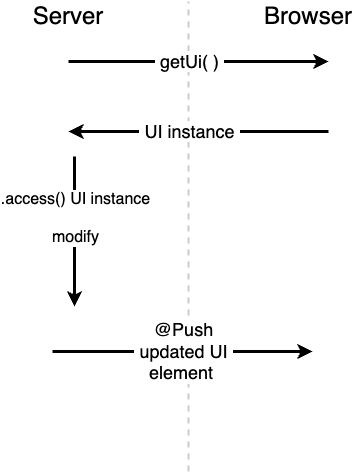
Normally you would add the @Push annotation above the Vaadin Layout element. But because we are using Quarkus, it works slightly differently. You have to place it somewhere else to enable Vaadin's push abilities application wide. There's a small file in /src/main/java/de/datenschauer called AppConfig.java which has been created automatically by the quarkus starter. There we have to add our @Push annotation:
@Theme("starter-theme")
@Push()
public class AppConfig implements AppShellConfigurator {
}And that's all. Now Vaadin has the ability to push updates from the server automatically to the client when they change.
But something is still missing! What do we do with the returned final ChatResponses from the model? We have to add the AiMessage to our chatHistory since by now it's still missing from there. For that purpose we have to create a method in our BasicStreamingChatModel to add the message to the history:
public class BasicStreamingChatModel implements Serializable {
...
public void addToChatHistory(ChatMessage aiMessage) {
chatHistory.add(aiMessage);
}
}And then in our handler we use a lambda function for the response and call the newly created method:
public class StreamingChatView extends VerticalLayout {
...
private void streamLLMResponse(ChatMessage userMessage, MessageListItem item) {
...
var handler = new MyStreamingHandler(
token -> {
...
},
// here we add the new method to update the history
// after the response is fully finished!
response -> model.addToChatHistory(response.aiMessage())
);
model.chat(userMessage, handler);
}
}Let's see how this works:
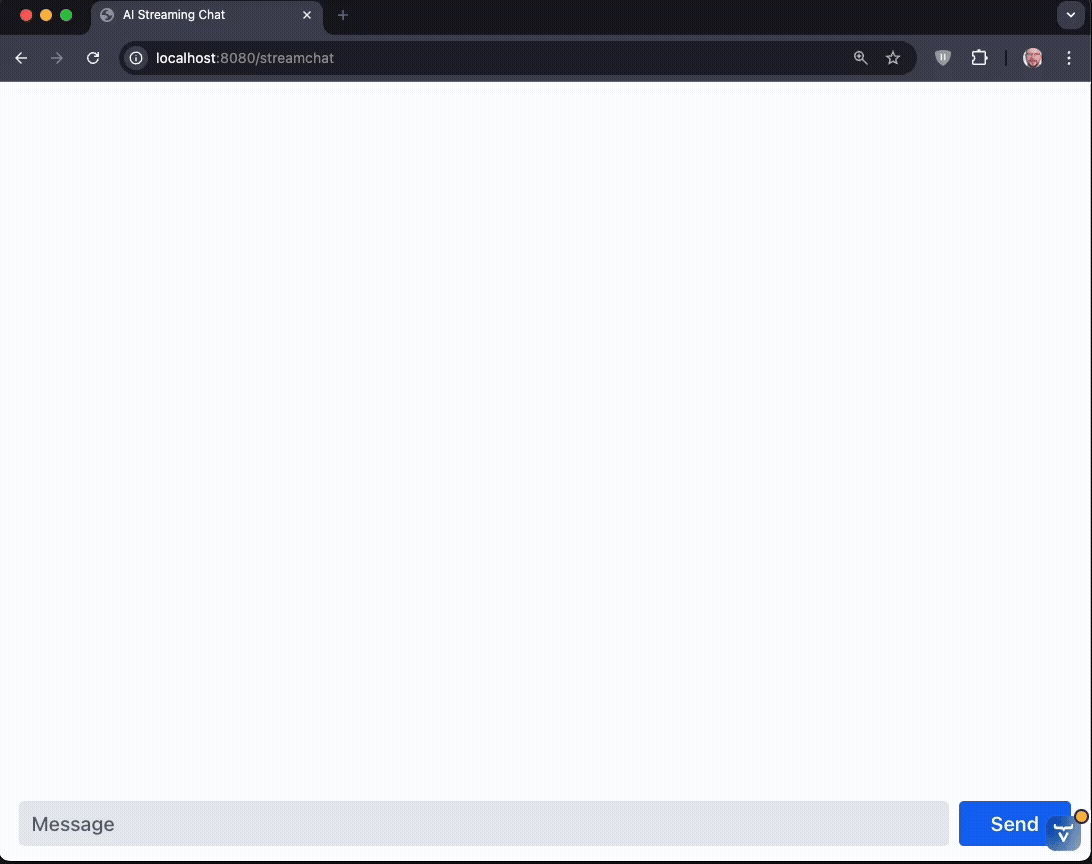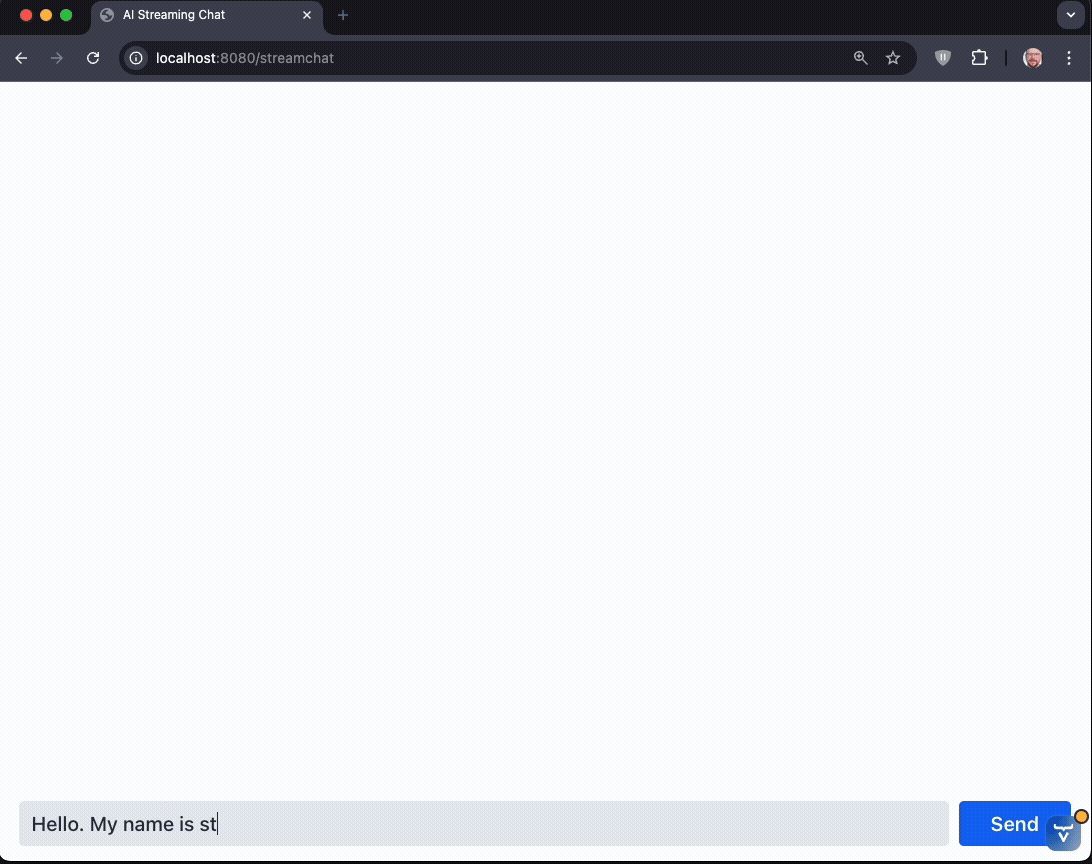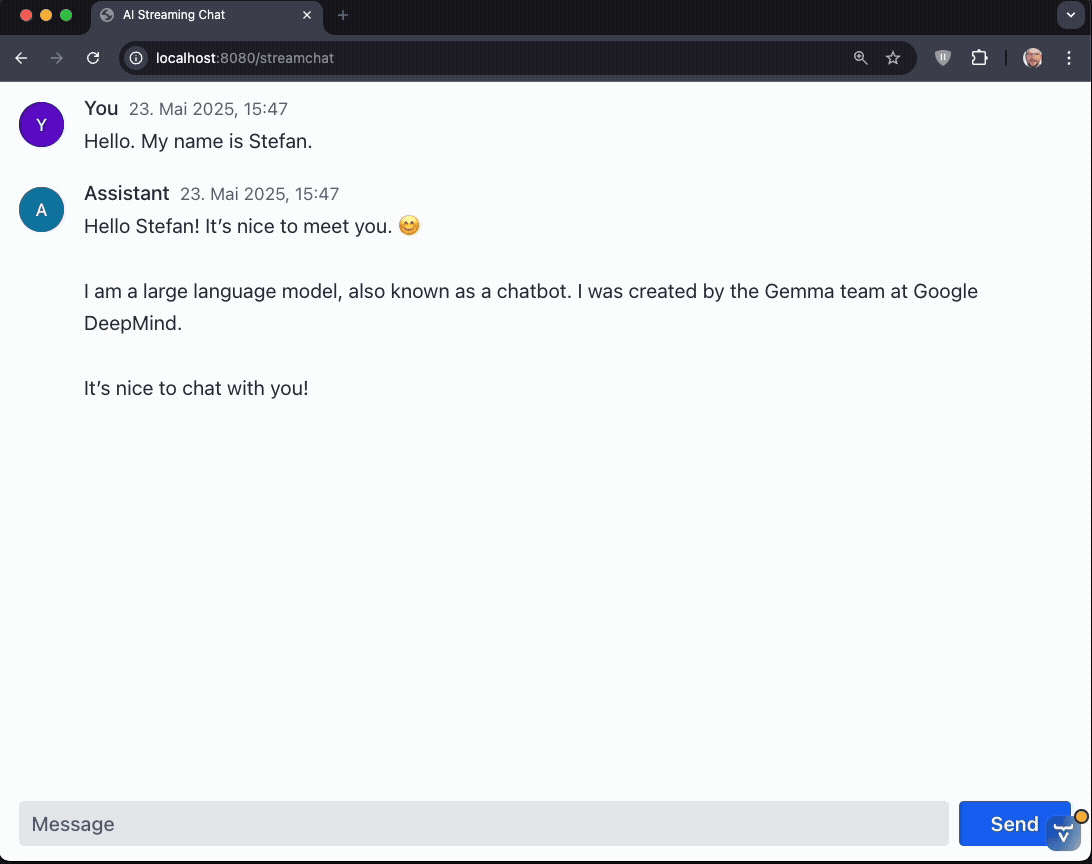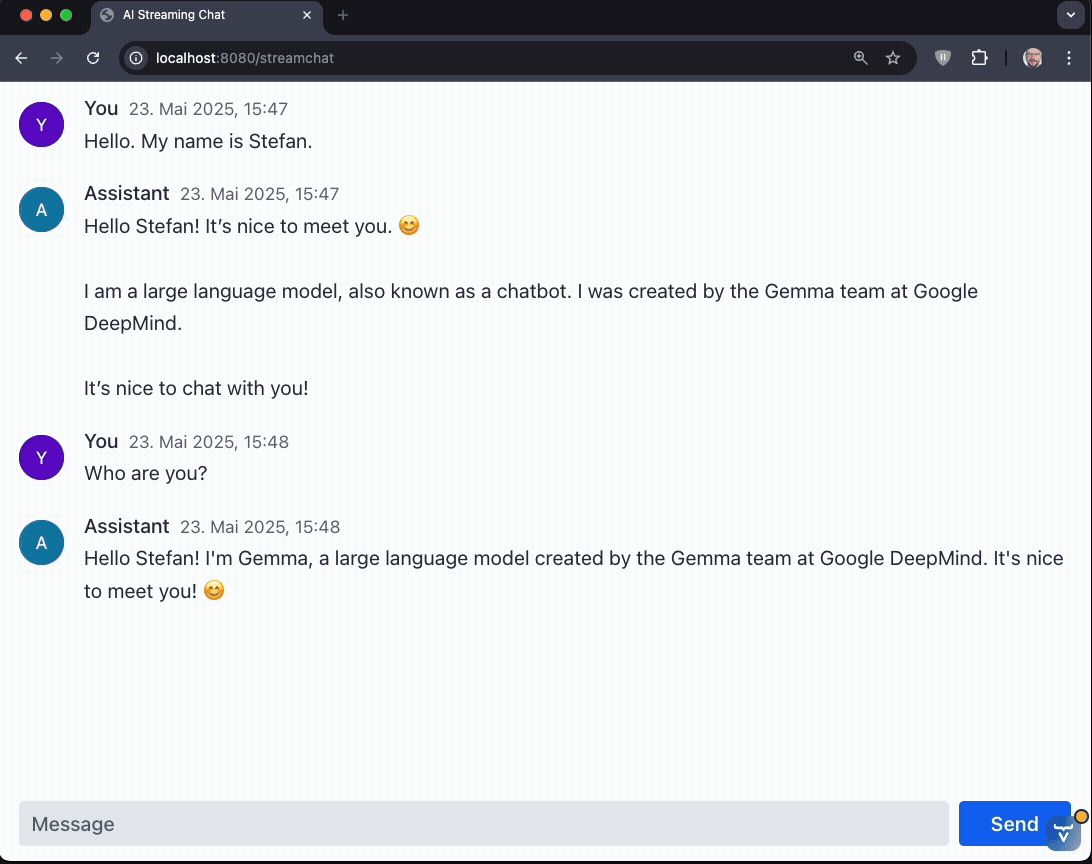
The stream is flowing! But still no markdown parsing so far. Let's change this.
Mark down!

Sadly this post is about just a few weeks too early, for a feature coming to Vaadin 24.8 in June 2025. This feature allows easy sanatized parsing of markdown in the MessageList directly:
getUI().ifPresent(ui -> ui.access(() -> {
item.setText(partialText.toString());
messageList.setItems(messages);
// new magic here! :-)
messageList.setMarkdown(true);
}));That's all! But because it's a pre-release feature, we have to change our pom.xml to fetch this prerelease. (Be aware, that after the changes we will get occasional warnings since we'll use the 24.8-SNAPSHOT version – I'm confident, June will come fast!)
So here is the new pom.xml:
After updating the pom.xml you should rebuild your installation with these commands:
rm -rf ~/.m2/repository/com/vaadin && \
mvn clean && \
mvn clean compile -ULater in the series we will get back to normal Vaadin release. But for now, the magic works and this is how the chat looks:
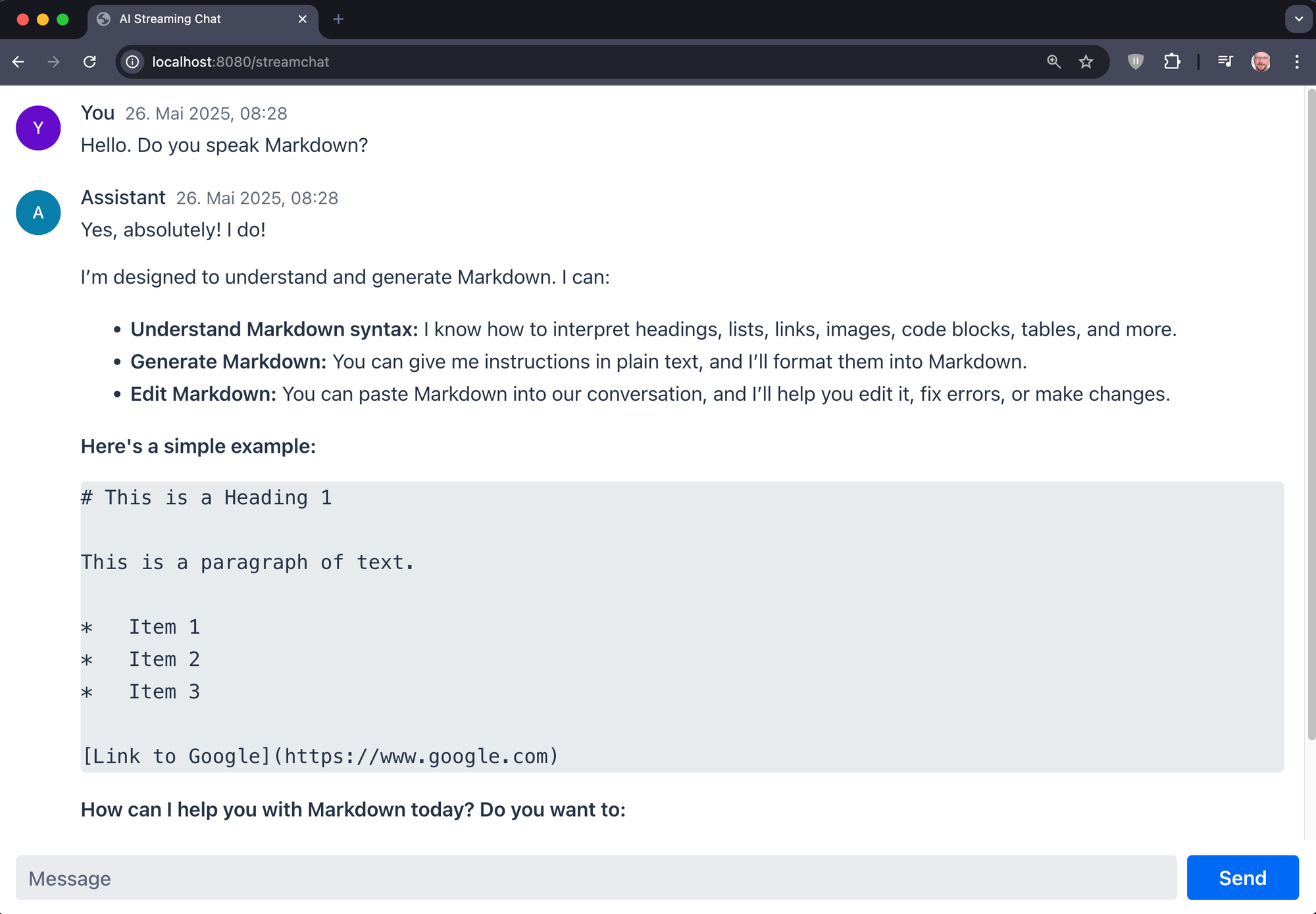
Awesome!
Next time: Memory
In our next part we will take a closer look, how to memorize context and chats for users. So we will add some identity management and some low level memory functions. After we've accomplished that I think it's good time to move on and look at some higher abstractions.
Until than! 👋
All titles in this series:
- Part 1: initial setup of tech-stack (Langchain4J, Quarkus & Vaadin)
- Part 2: adding streaming capabilities and markdown formatting
- Part 3: adding chat history and memory