AI Engineering in Java with Langchain4J, Quarkus and Vaadin

This is the first and initial part of an open ended series about building AI driven (read: “LLM driven”) applications in Java. The series will follow ruffly the structure of the Langchain4J and Quarkus-Langchain4J extension's documentations. So I unashamedly and selfishly use this series to jot down my own explorations and experiences with the topic. Here is a sketch of the libraries and technologies I plan to use:
- Quarkus as the backend framework
- Langchain4J as the LLM framework
- Ollama for running LLMs locally
- Quarkus Langchain4J Extension to integrate the LLM framework into Quarkus's concepts more easily
- PgVector, a PostgreSQL Extension as vector database
- jOOQ for some low-level interactions with the database
- Vaadin for fast frontend sketches in pure Java
Why did I choose this stack? Because these are the tools I am mostly familiar with! 😄 In our projects we use Quarkus and PostgreSQL already. And in my research area and lectures I'm using Ollama and Langchain (the Python version!) a lot. Therefore it feels quite natural for me to use these tools. But I will certainly also inspect SpringAI and ADK in the near future.
Warning: In my explorations I often start from the bottom, not from the easier abstractions, the used frameworks propagate (and for good reasons!). I often try to get my head around the underlying concepts and then work my way up from there.
All titles in this series:
- Part 1: initial setup of tech-stack (Langchain4J, Quarkus & Vaadin)
- Part 2: adding streaming capabilities and markdown formatting
- Part 3: adding chat history and memory
Install requirements
For the setup to work, you need to have installed the following software: Docker for spinning up the database in development mode and Ollama for serving the large language model locally.
Docker
Follow the installation instructions for your operating system at https://docs.docker.com/desktop/.
When everything's set up correctly you should be able to issue docker --version at the command line without any error.
Ollama
With Ollama we'll be able to choose different models (see: https://ollama.com/search) and serve them locally.
To install Ollama follow the instructions on this site. When installed sucessfully, you can pull a model (e.g. ollama pull gemma3:4b) and spin up the Ollama server with ollama serve. It runs on port 11434: http://localhost:11434. To see all the models on your machine issue ollama list. To see all loaded models: ollama ps. You can easily remove models with ollama rm <model_name>.
To see if everything works, enter ollama run gemma3 (if you pulled gemma3 from above, or any other model name you pulled) and you should get a cli chat interface to interact with the model via console.

Setting up the project
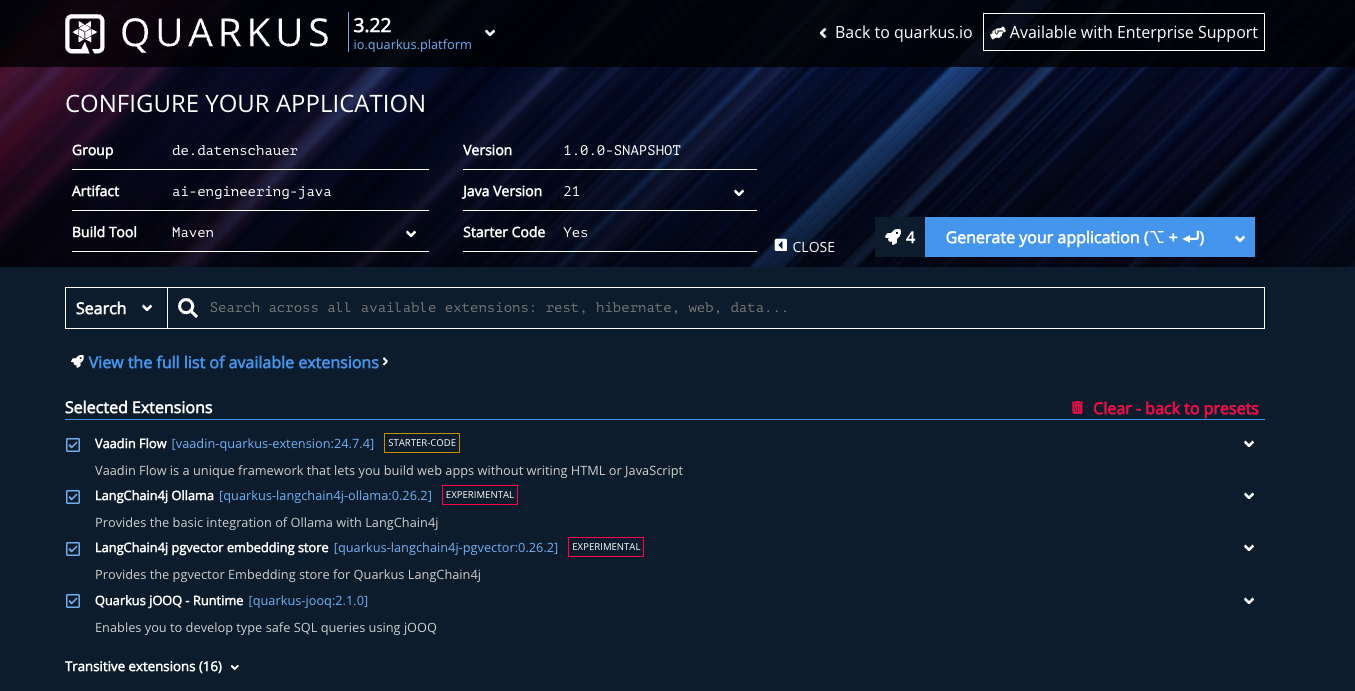
Head over to code.quarkus.io, where you can download Quarkus already bundled with the following extensions and dependencies:
- Vaadin Flow
- Langchain4J Ollama
- Langchain4J pgvector embedding store
- Quarkus jOOQ - Runtime
Alternatively you can use this repository on Codeberg where I share my code. The main branch should reflect the current state of the project and the different branches the parts of this series.
Verifying everything is set up correctly
Head to the directory of the cloned repo or unzipped file you downloaded from code.quarkus.io and enter mvn verify. (Alternatively, if you haven't installed Maven you can use the Maven Wrapper cli tool mvnw provided with Quarkus: ./mvnw verify. Be sure mvnw has execution rights: chmod +x mvnw.)
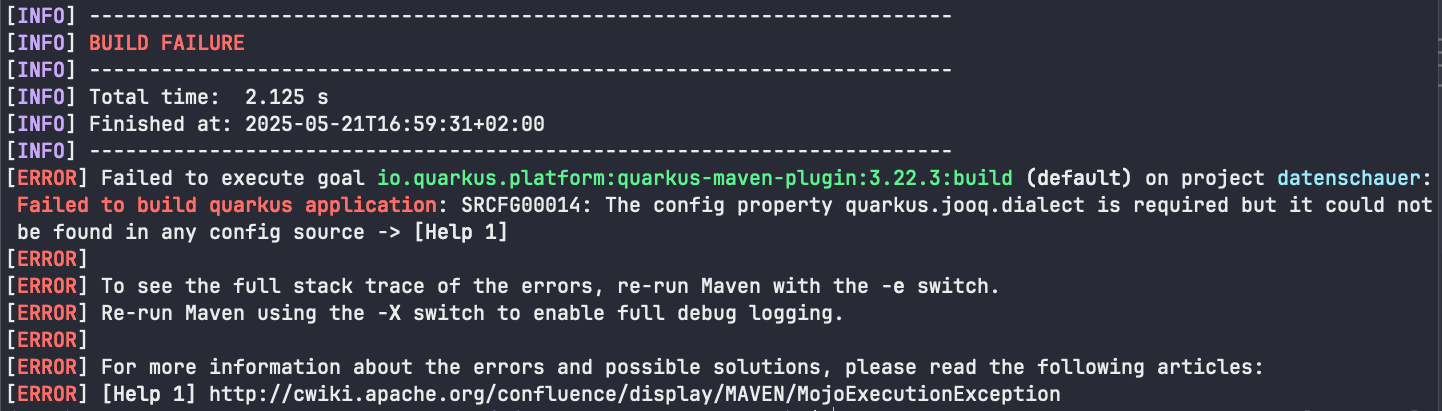
At first run the build will fail due to a required setting of the dialect for jOOQ. We can quickly fix this! Head over to /src/main/resources/application.properties (Quarkus's main configuration-file – more here) and add the following line: quarkus.jooq.dialect=POSTGRES. After saving these changes the build should succeed.
Now we can test if Quarkus is actually starting up with mvn quarkus:dev. But – oh no! another error! 🙈
io.smallrye.config.ConfigValidationException: Configuration validation
failed:
java.util.NoSuchElementException: SRCFG00014: The config property quarkus.langchain4j.pgvector.dimension is required but it could not be found in any config source
For Quarkus to automatically spin up a docker container for its dev capabilities and providing a PostgreSQL cluster out of the box with the pgVector extension enabled, we have to set the dimension for the vectors, which we like to store later. Don't worry, we change the exactly needed dimension later. For now any integer will do! So we enter the following line to our application.properties:
quarkus.langchain4j.pgvector.dimension=1024
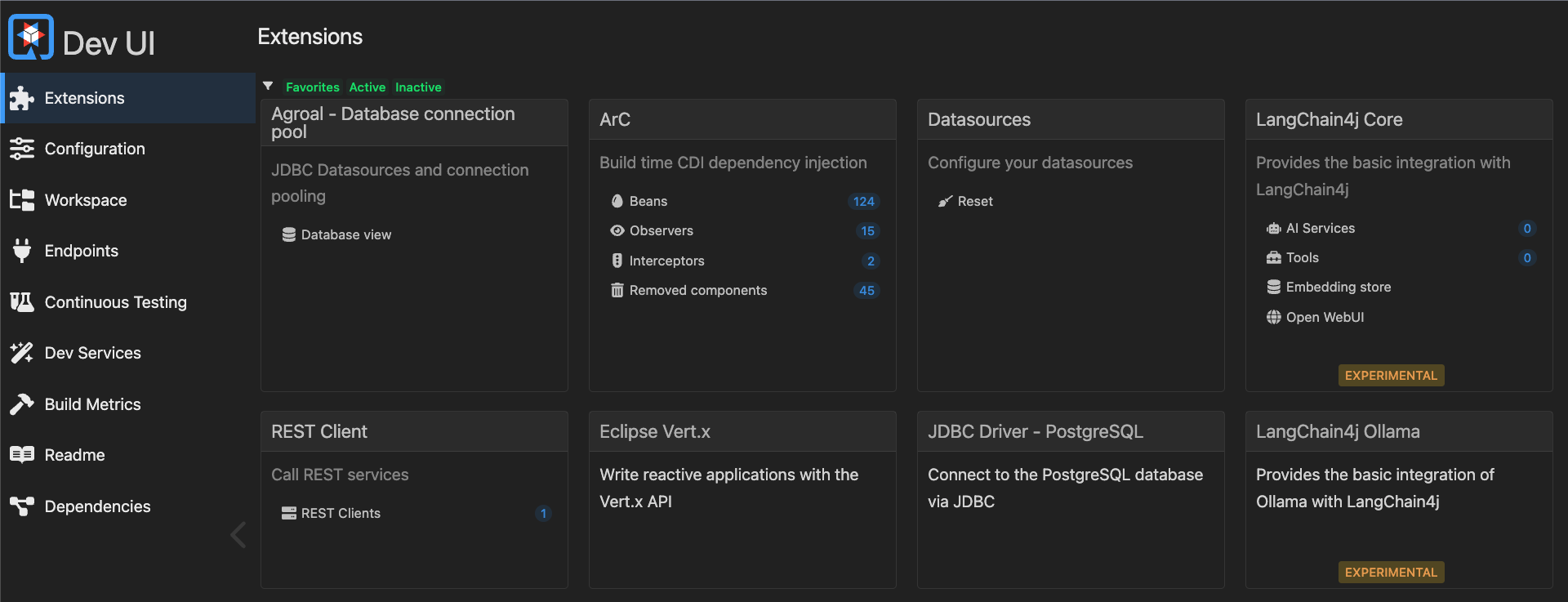
When we shut down (ctrl-c) the Quarkus server and run it again with mvn quarkus:dev, everything should go fine and we can try to enter http://localhost:8080/q/dev-ui in our browser. And voila, the Quarkus Dev-UI should spin up:
Adding our first AI chatbot
The basic building blocks of the Langchain4J application for communicating with the LLMs is the ChatLanguageModel interface, which accepts multiple ChatMessages. There are different implementations of the ChatMessage interface: the most important ones for us right now are SystemMessage, UserMessage and AiMessage. You hand the ChatMessagesss over to the ChatLanguageModel via a ChatRequest object and you get back a ChatResponse object (there's still the possibility to hand over a simple String and return a String, but this should be avoided!).
Of course we need the right implementation of the ChatLanguageModel interface for our purposes which is the OllamaChatModel. The Model, Request and Response classes are to be constructed via a builder pattern. So let's create a folder src/main/java/de/datenschauer/ai and within it a BasicChatModel.class.
public class BasicChatModel {
static final String MODEL_NAME = "gemma3";
static final String BASE_URL = "http://localhost:11434";
OllamaChatModel model;
public BasicChatModel() {
this.model = OllamaChatModel.builder()
.modelName(MODEL_NAME)
.baseUrl(BASE_URL)
.httpClientBuilder(new JdkHttpClientBuilder())
.build();
}
}As you can see, the basic configuration of a OllamaChatModel are the MODEL_NAME, which has to be one of Ollamas pulled models (list via ollama list) and the URL where Ollama serves the models. Just a little note: we also added the builder method .httpClientBuilder(new JdkHttpClientBuilder()). We need to add this since we are using pure Langchain4J at this stage and not the corresponding Quarkus Extension. When we would start up Quarkus without this method, Quarkus wouldn't know which HTTPClient it should use to connect to the Ollama Server. So we explicitly inject it here.
To interact with the model we need a chat() function, which takes in a ChatRequest and returns a ChatResponse. The ChatRequest also uses a builder pattern and wants a List of ChatMessages. So we add this to our class:
@SessionScoped
public class BasicChatModel {
...
List<ChatMessage> chatHistory = new ArrayList<>();
...
public ChatResponse chat(final ChatMessage userMessage) {
chatHistory.add(userMessage);
ChatResponse reply = this.model.chat(
ChatRequest
.builder()
.messages(chatHistory)
.build()
);
chatHistory.add(reply.aiMessage());
return reply;
}
}Right from the start we follow the idea, that users want to actually chat with the model, which means that the model shall remember the conversation for their answers. LLMs are stateless! So alle previous messages must be sent anew to the model to remember previous questions, instructions, answers and outputs.
We also added the annotation @SessionScoped so we can inject the model everywhere in our application where it is needed (if you are unsure about the workings of CDI in Quarkus or other Jakarta EE frameworks, see for example this documentation). Also: @SessionScoped means that the Bean is created anew for every session, which is ok for us right now as we don't save chat histories across sessions for a user.
Now to test and play with the ChatModel I could use a REST endpoint, but I like little UI elements. So let's build a rudimentary chat UI with Vaadin!
Building the chat UI with Vaadin
Building the UI with Vaadin in its current version is really easy and Vaadin gives us a lot of convenience classes and functions for this purpose.
Create a folder /src/main/java/de/datenschauer/ui and there a class ChatView.class with the following content:
@Route("/chat")
@PageTitle("AI Chat")
public class ChatView extends VerticalLayout {
@Inject
BasicChatModel model;
private static final String USER_NAME = "You";
private static final String AI_NAME = "Assistant";
private final MessageList messageList = new MessageList();
private final List<MessageListItem> messages = new ArrayList<>();
public ChatView() {
setSizeFull();
setSpacing(false);
setPadding(false);
setMargin(false);
messageList.setWidthFull();
messageList.setHeightFull();
messageList.setItems(messages);
MessageInput messageInput = new MessageInput();
messageInput.setWidthFull();
messageInput.addSubmitListener(e -> handleUserMessage(e.getValue()));
add(messageList, messageInput);
}
private void handleUserMessage(String text) {
if (text == null || text.trim().isEmpty()) return;
MessageListItem userMessageItem = new MessageListItem(
text.trim(),
Instant.now(),
USER_NAME
);
userMessageItem.setUserColorIndex(1);
messages.add(userMessageItem);
messageList.setItems(messages);
ChatMessage userMessage = UserMessage.from(text.trim());
getLLMResponse(userMessage);
}
private void getLLMResponse(ChatMessage userMessage) {
ChatResponse aiReply = model.chat(userMessage);
MessageListItem aiMessageItem = new MessageListItem(
aiReply.aiMessage().text(),
Instant.now(),
AI_NAME
);
aiMessageItem.setUserColorIndex(2);
messages.add(aiMessageItem);
messageList.setItems(messages);
}
}We just use the predefined Vaadin components MessageList (Docs) and MessageInput (Docs). Also the accompanying MessageListItems build very nice ui elements right from the beginning. Let's head over to https://localhost:8080/chat and see how this looks:
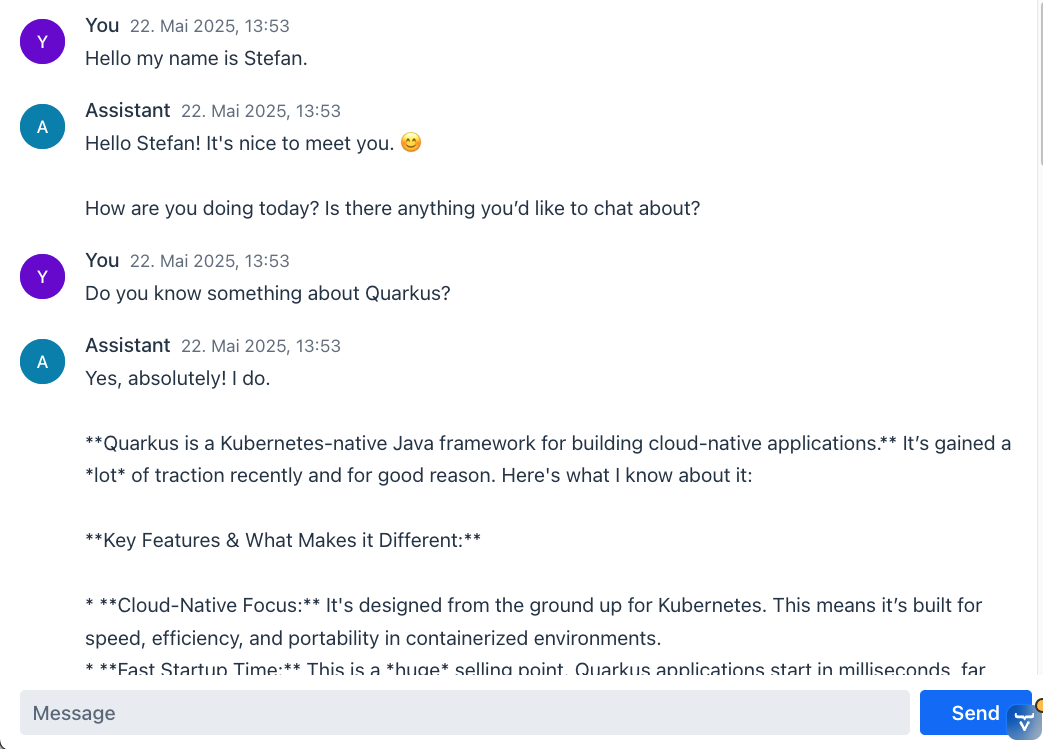
I think that's a very impressive result for just a view lines of code and we didn't even draw into account the bigger abstractions, the Quarkus Langchain4J Extension gives us. Also Vaadin is really doing an amazing job, giving us out of the box components to work with and build proof of concepts.
What's up next?
But there's still a lot to do! As you can see, the output of the ChatModel is in markdown format. We would do good, to parse it correctly and show the correct formatting in html. Another thing which you would complain about instantly is the gross lag between the user input and the appearance of the LLM's output. Wouldn't it be nicer if the LLM would start immediately to stream it's output – token per token (like ChatGPT's behavior)? And lastly can't we get some persistent memory between sessions?
So these are the things we will implement in our next session:
- Parse and format the markdown output.
- Making streaming of individual tokens to the chat message list possible.
- Incorporating a low-level chat-memory with Postgres.
See you next time! 👋


